Context Cards
Discovering the concept
Why context: It is not necessary that audiences will know the context of current news events.
- The absence of context makes audiences susceptible to misinformation.
- Additionally, providing historical facts and data increases a users’ confidence in a news source.
Why automate: Newsrooms are optimized to stay on top of the news cycle and publish news fast and in vast quantities. Given this:
- It isn’t always possible for the newsroom to research the archive to write the context.
- Additionally, even if it is written, it is unlikely that the newsroom will be able to keep it updated.
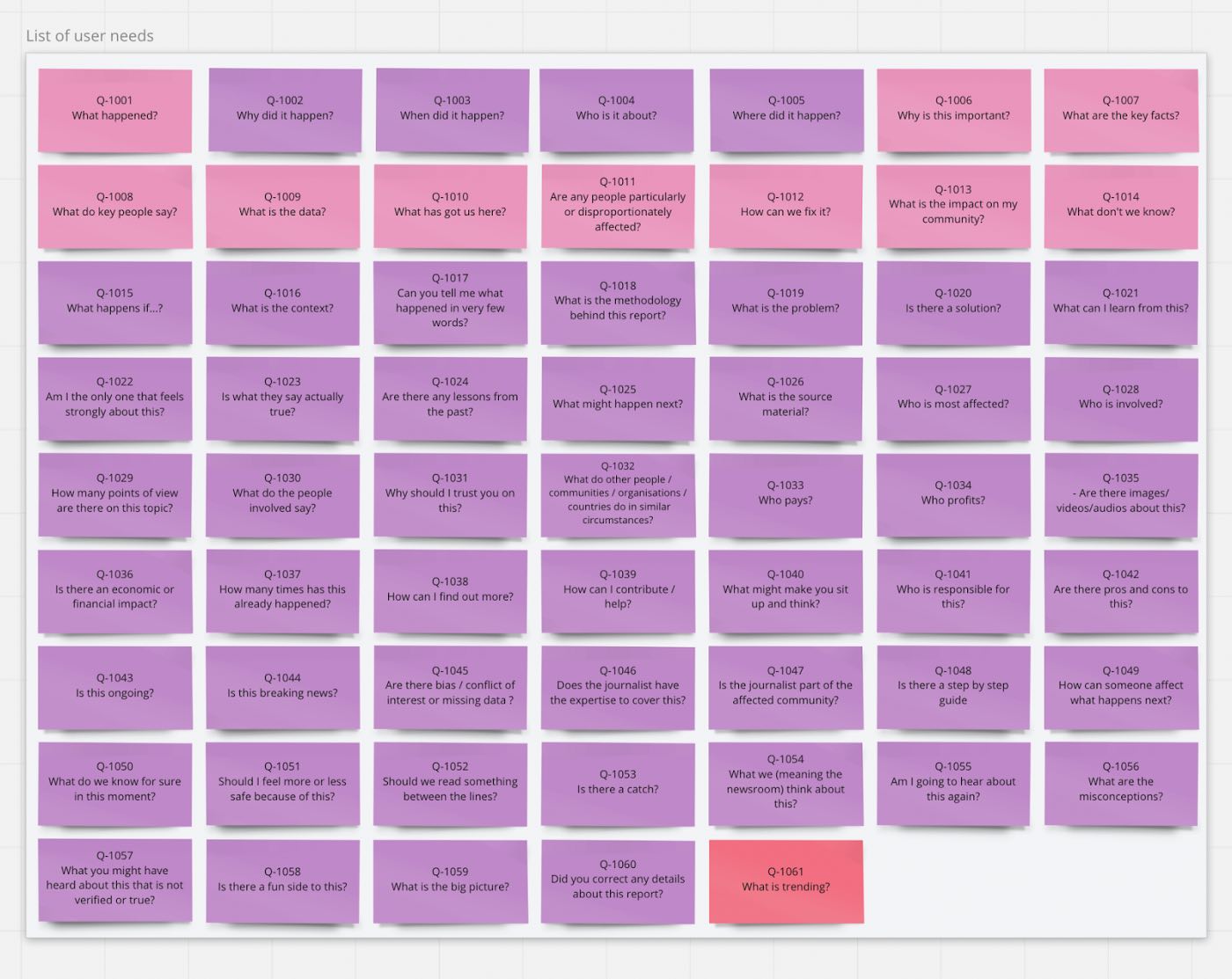
The need for structure: News covers a variety of topics — Sports, Politics, Business, Economy, Personal Finance — and there is no clear demarcation of where a particular topic will be found. We built upon the SIXTY user needs questions identified in modularjournalism.com by Clwstwr, Deutsche Welle, Il Sole 24 Ore and Maharat Foundation as part of the JournalismAI Collab Challenges 2021 / EMEA.
Over the last few months, the concept evolved as we discovered more nuances. Below are blog posts from then. The last piece that was published in the Polis LSE blog is the clearest version of what we intend to build. The other two demonstrate our thoughts in its evolutionary process.


Discovering the user experience
The concept of context as product is not novel. It has been around in multiple shapes and forms. Below are some of the examples we curated for inspiration.
Examples from news products
Inserts in Semafor articles

Volv’s Timeline

Circa’s Follow Button
Examples from BigTech
Twitter’s Event Page
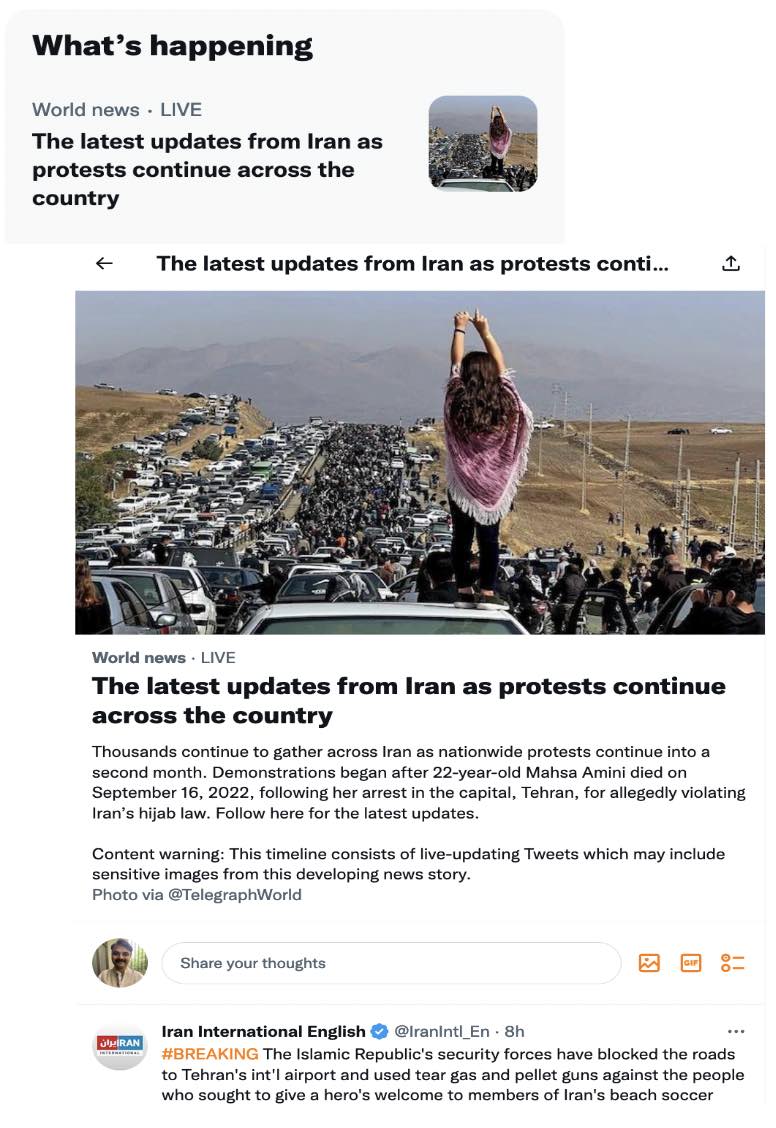
Twitter’s Community Notes
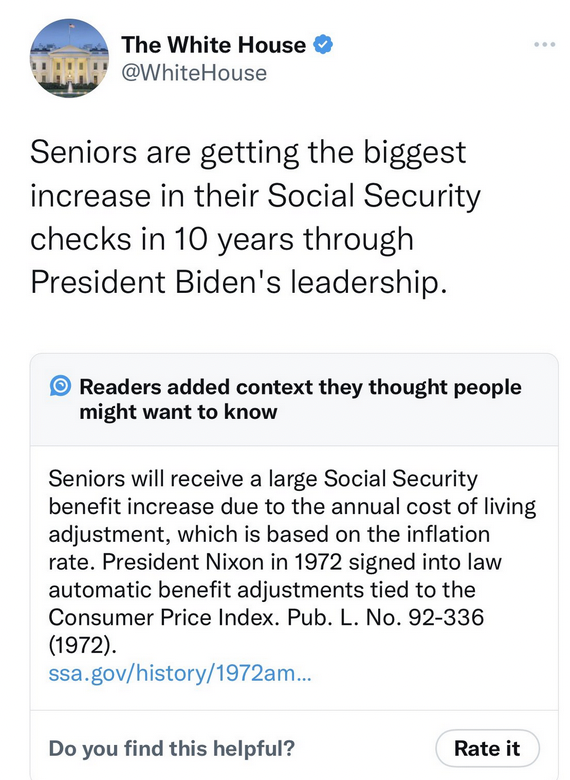
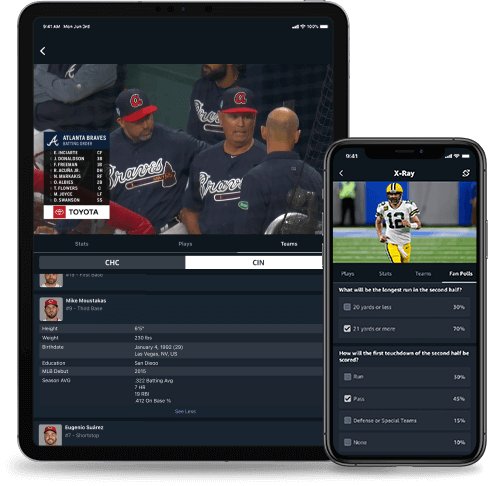
Amazon Prime Video X-Ray
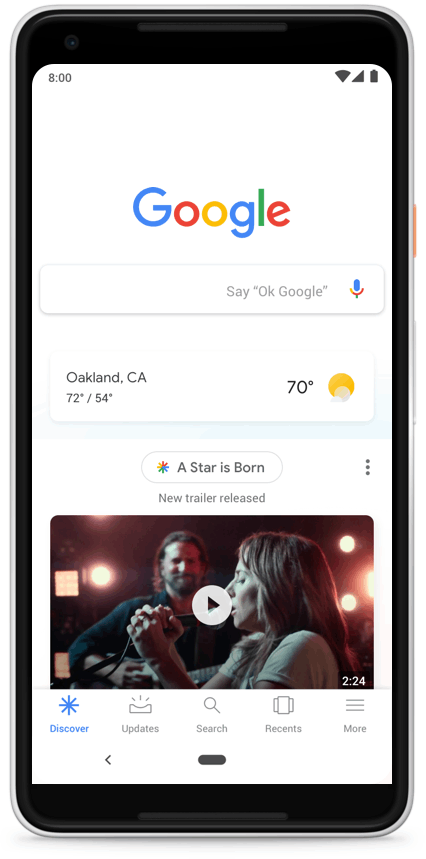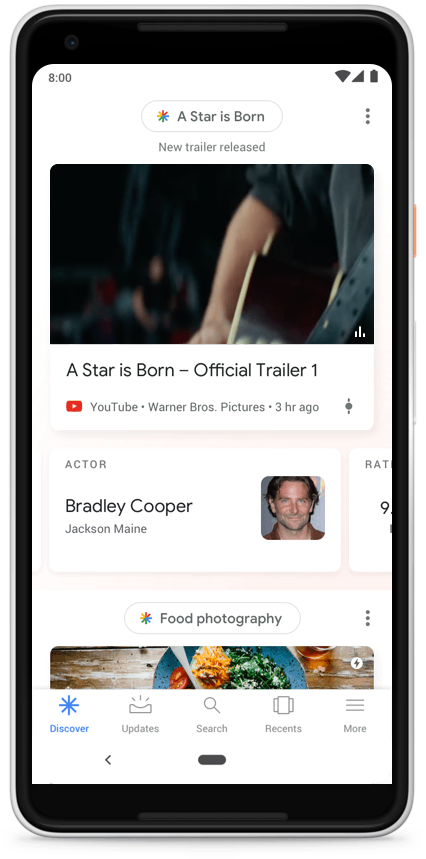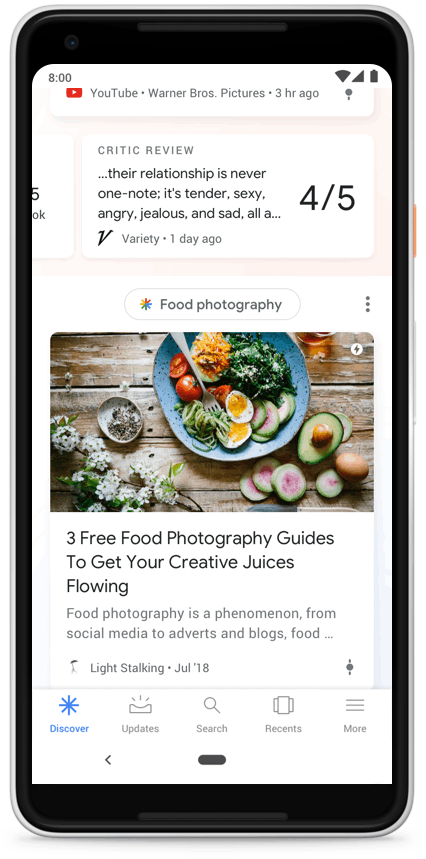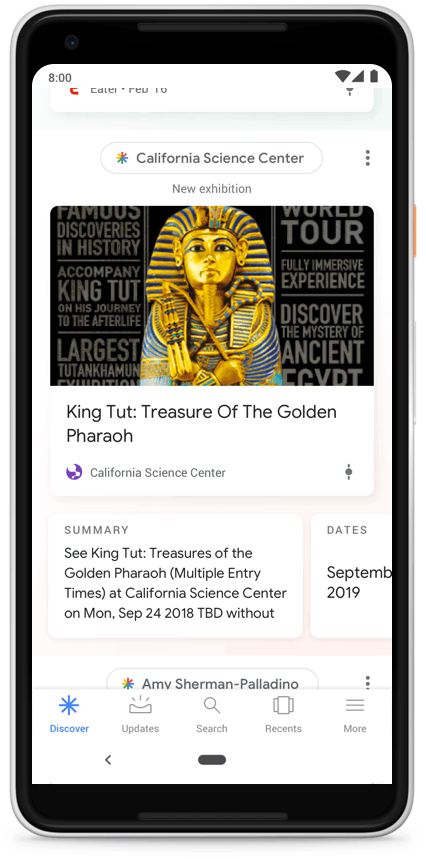
Google News Full Coverage
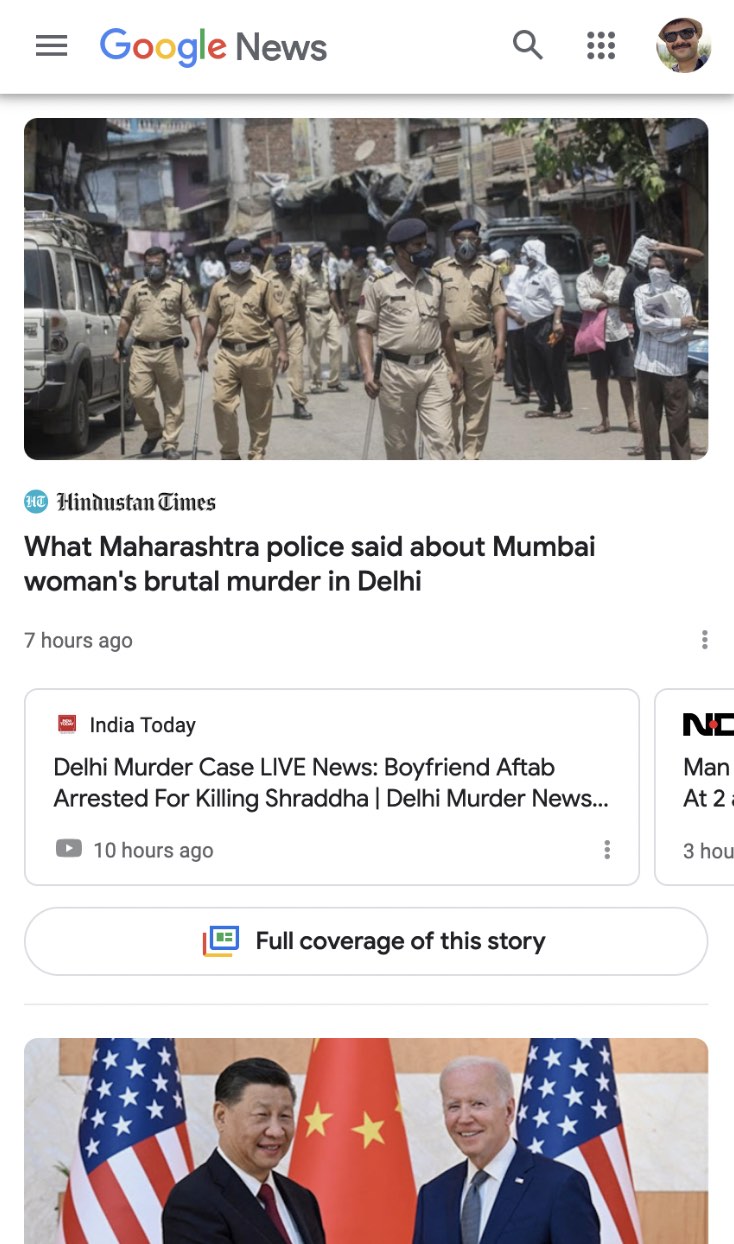
The team discussed multiple design options but eventually concluded to stick to cards as a design concept.

The final UX: When a user is reading an article, they gets a prompt or nudge at the bottom sticky footer. For the copy of the prompt, we decided to use the user needs questions defined as part of modularjournalism.com. On clicking it, a bottom sheet opens and showcases context.
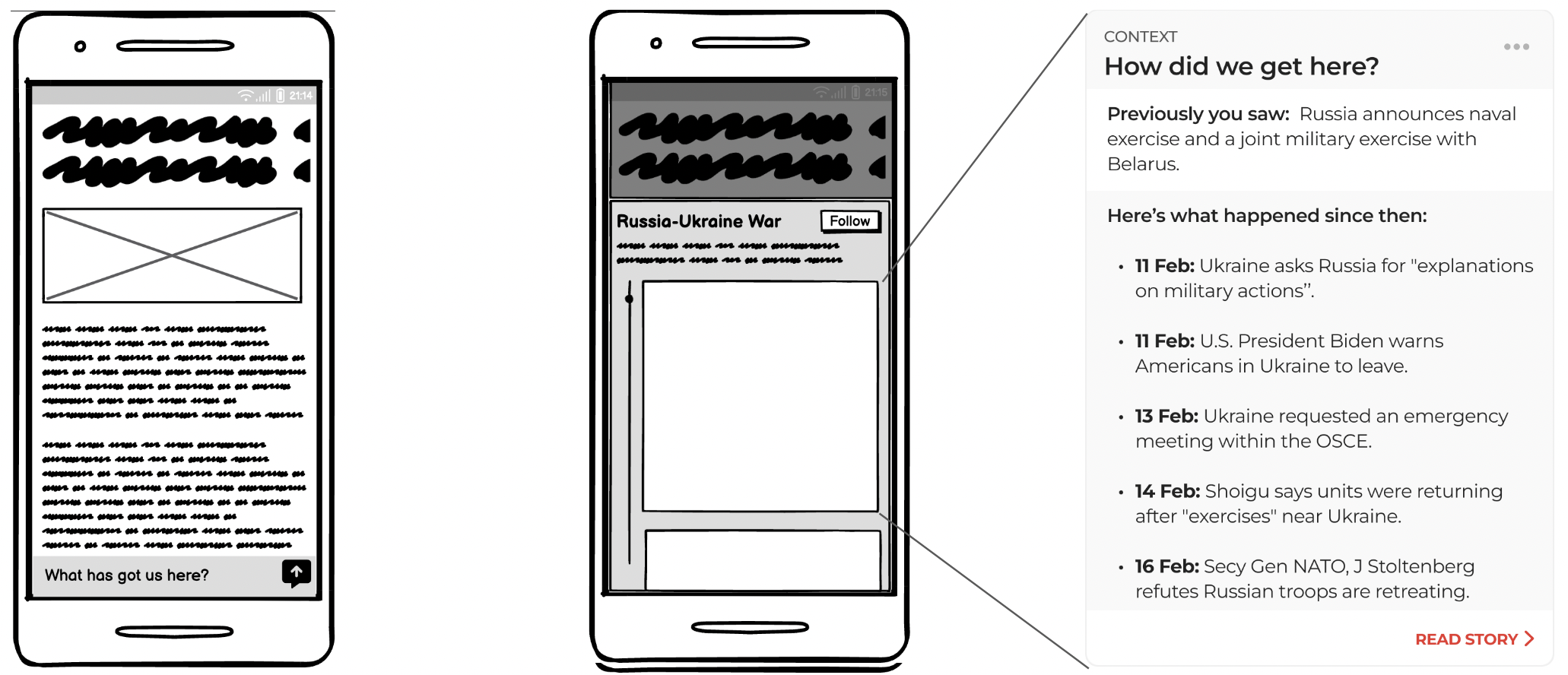
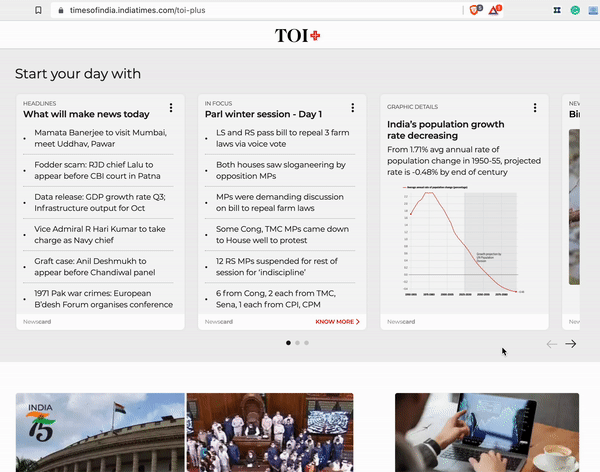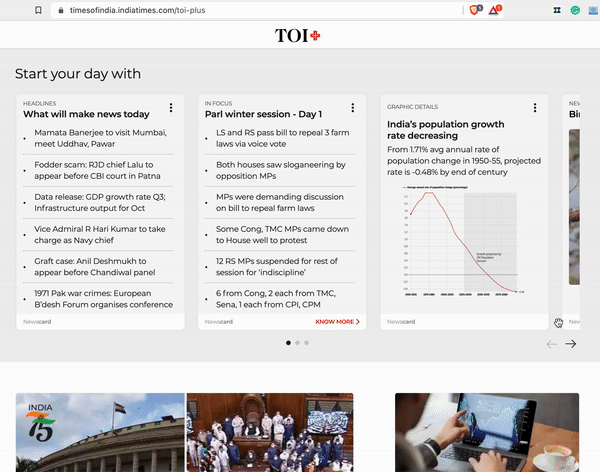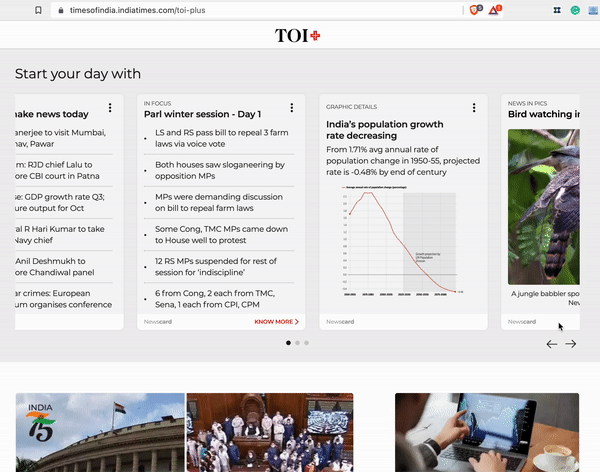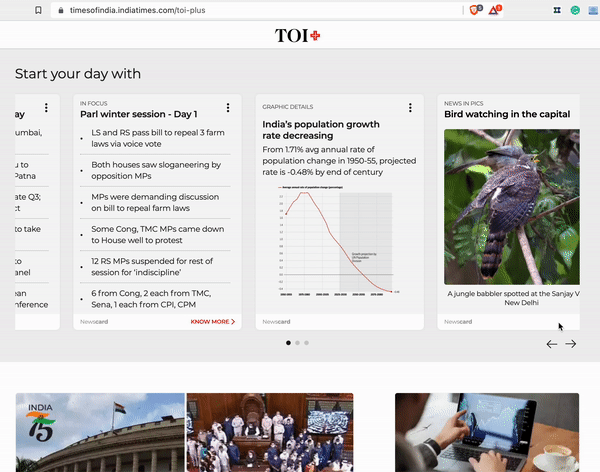
How the product will look
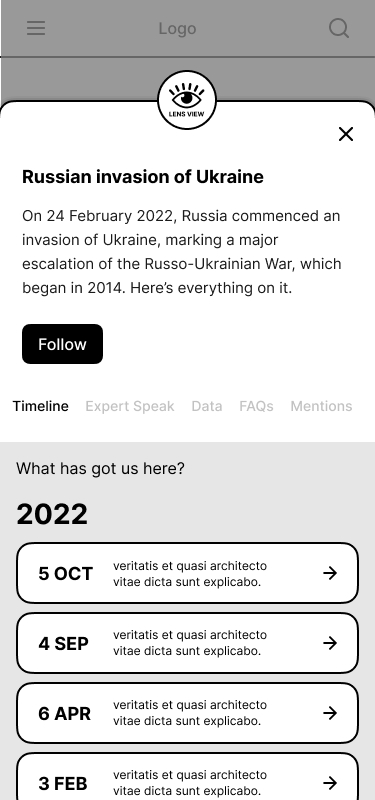
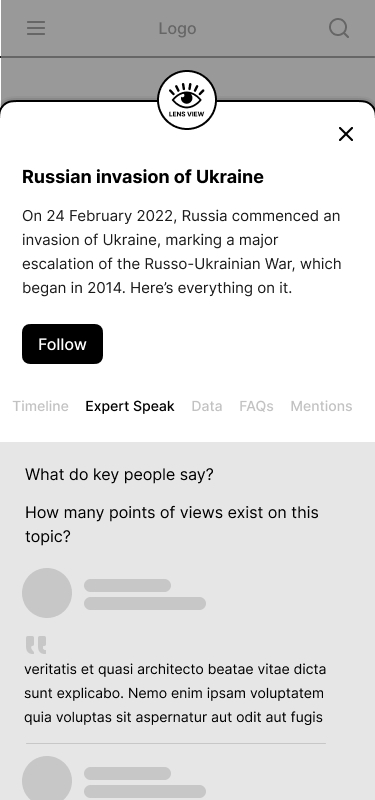
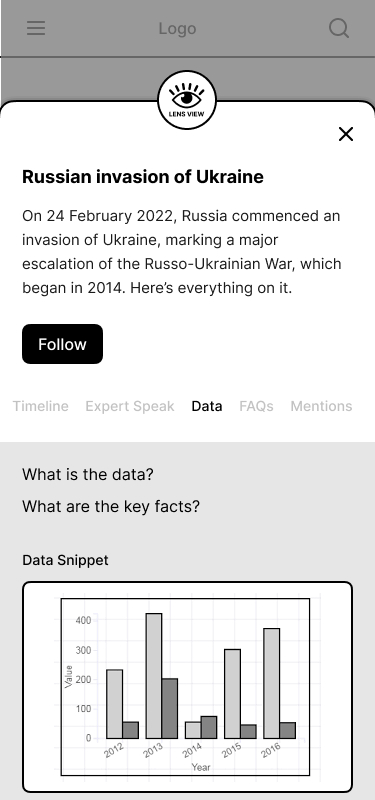
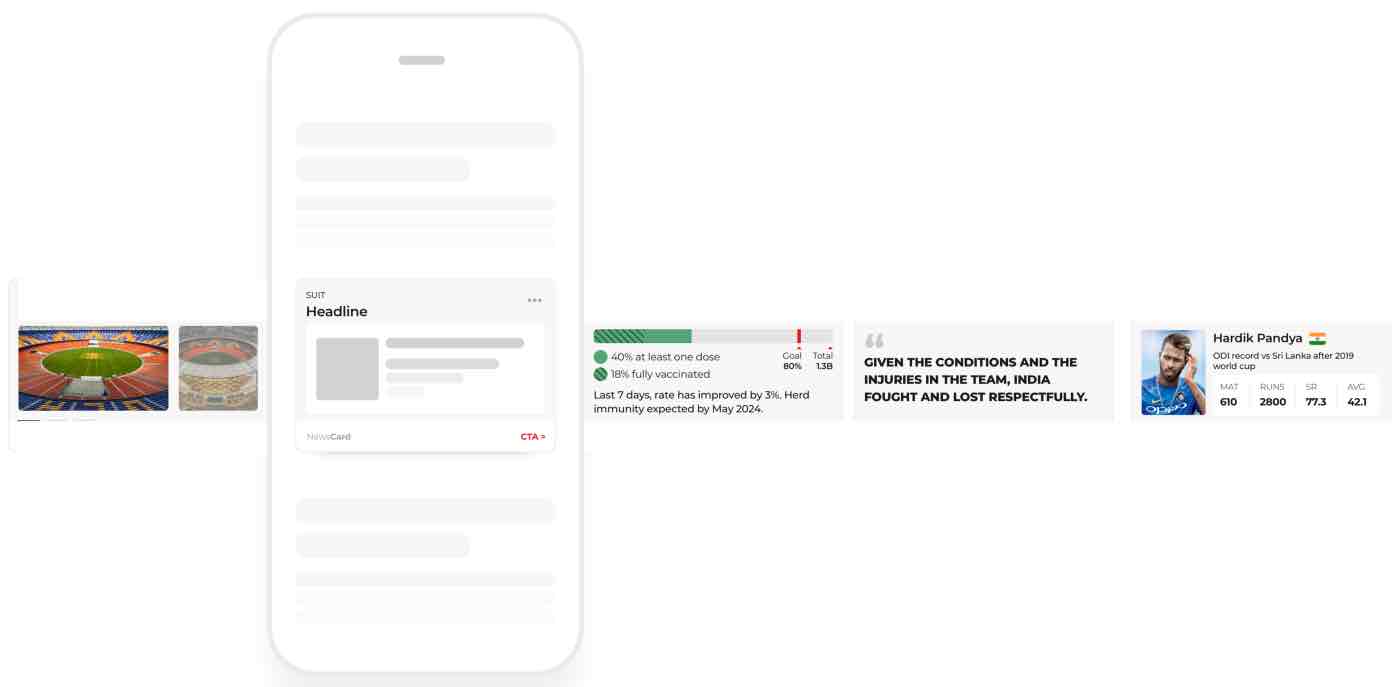
We referred to the algebra of modular journalism and from 60 user need questions, we came up with five card ideas for providing context.
- Timeline: The timeline card tells what happened when.
- Expert Speak: This card tells who said what.
- Data: This card shares relevant facts.
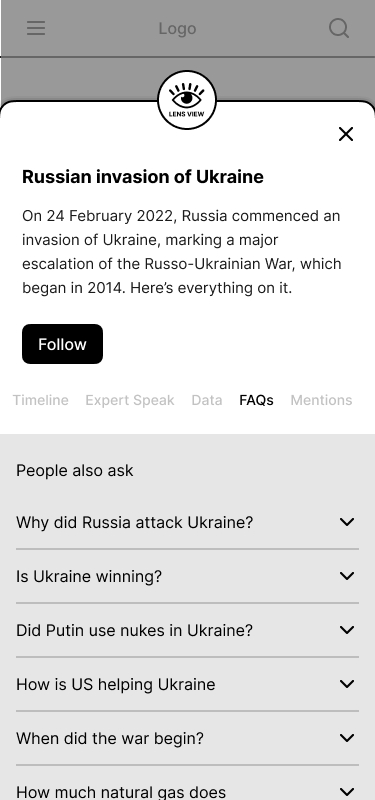
- FAQs: This card answers most popular questions on this newscycle
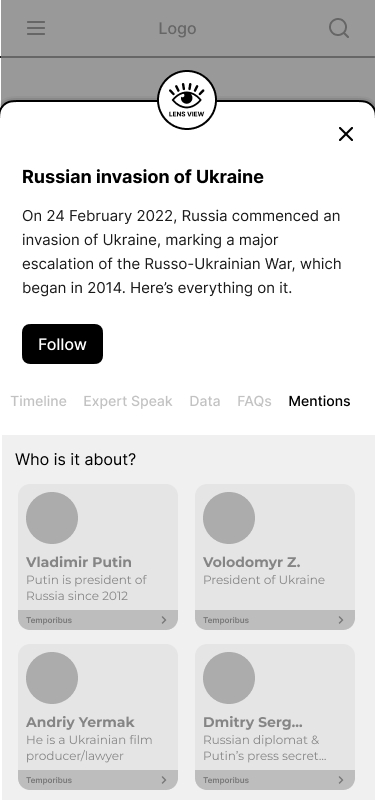
- Mentions: This card gives information about the most relevant stakeholders in the given newscycle.

Step 1: Topic modeling
Editors publish stories in relevant sections and subsections such as sports, cricket, tennis, world, US, politics, general elections, etc. However, online users are more interested in specific obsessions or hash tags, for example, Russia Ukraine War. Hence, the first step, was to invest in an algorithm to cluster the archive around news cycles instead of sections.
For this, we explored Topic Modeling algorithms. You can find our detailed evaluation in the below two blogposts:
Step 2: Generate copy for the context cards
To find the context we will use machine learning to go through all articles in a given newscycle which will pick the relevant information/facts that are then displayed in our five Context Cards. For this step, we explore two options:
- Using pre-trained small language models
- Using OpenAI’s GPT-3
Option #1: Pre-trained small language models
Once we’ve bucketed the archive into topics, we intend to build the following cards/modules using ML:
Most context is at the news cycle level and not at the story level. Hence, whenever a user sees one story, contextually, we show a bottom sheet with: Headline, Description, Follow button.
For now, both will be written by the editor because its workflow can be tied to the supervision required on top of the topic modelling algorithm. You can read more about it in the blogpost Refining topic modeling to automate taxonomy
[Timeline] What has got us here?
There are three ways to implement the timeline:
Method 1: The simplest option is to list out all related stories from the topic modeling model in descending order. To reduce the number of stories, we intend to combine each story with page views data and only show the stories that received higher page views than a certain threshold. However, this approach does not make for an elegant reading experience.
Method 2: We also considered using small language models like winkjs.org that identifies sentences with references to time. You can then pull these sentences out and then sort them to publish a timeline. However, this requires some behavioral shift in how Editorial writes articles and would also require significant post-processing.
Method 3: Ideally, we ought to have run another topic modeling algorithm on the stories from within a news cycle and cluster those stories into events. Finally, we run the summarization algorithm on top of stories within an event to generate the timeline.
[Expert Speak] What do key people say? How many points of view are there on this topic?
The list of opinion stories can be easily fetched from querying the content warehouse.
For extracting quotes, we intend to build on the quote extraction model built by The Guardian in an earlier iteration of JournalismAI.
[Data] What is the data?
To build this, we will reuse the broad methodology followed by the Guardian to extract quotes but deployed on extracting statements where data is quoted.
[FAQs]
The tab mimics the “People Also Ask” feature from Google.
Our first thought was to use OpenAI’s GPT3 Q&A APIs. In fact, most GPT3 powered text editors or writing assistants provide a FAQs for SEO feature. However, OpenAI accepts text only in chunks of 500-1000 words. This means, the AI won’t generate Q&A after reading all the stories. This might not be correct.
Hence, we plan to build our own Question Answering models.
[Mentions] Who is it about? Who is involved?
For this, we intend to use Named Entity Recognition models. We tried out Spacy and observed significant noise which we reduced by filtering out entities recognized by NER but not found in Wikidata.
TOI’s internal CMS already does entity tags and maintains topic pages for these entities. Another approach could be to build on this itself instead of reinventing the wheel.
https://huggingface.co/spaces/context-cards/NER-context-card-streamlit
Option #2: Using GPT-3 davinci-003
OpenAI released GPT-3’s latest upgrade—davinci-003 in November 2022. We decided to try it out for generating content for Context Cards. Here is a summary of what we found:
- GPT-3’s ability to give a summary is like magic
- GPT-3 will have a knowledge gap on developing stories and hence it tends to get facts wrong
- In its attempt to be contextual, GPT-3 tends to be parochial
GPT-3 will surely help speed up the process to get the first draft. However, we’ll still need senior editorial supervision and review of the content generated before it can be published as context cards. Read more about findings in the blog below.

Step 3: Presenting the content
For this, we’ll be using Newscards, which is a modular content CMS. More on this in the below blogposts.

Reactions
Credits
- All of this was possible because of the JournalismAI Fellowship programme run by JournalismAI at POLIS at the London School of Economics and Political Science:
- Charlie Beckett
- Mattia Peretti
- Lakshmi Sivadas
- Mentors:
- Dr. Tess Jeffers of Wall Street Journal
- Shirish Kulkarni of Clwstwr
- Manish Mishra and Gyan Mittal, Times Internet
- Team:
- Ritvvij Parrikh, Director of News Products, The Times of India
- Karn Bhushan, Data Scientist, The Times of India
- Amanda Strydom, Senior Programme Manager, Code for Africa